エージェント スキルは、手順的な知識を標準化してカプセル化する方法です。つまり、解決するのは「ツールがあるかないか」ではなく、「ツールを正しく上手に使う方法」なのです。
1. 核となる設計コンセプト
エージェント スキルの中核となる価値は、「方法論」の蓄積にあります。
- 特定のシナリオでツールを組み合わせて呼び出す方法をエージェントにガイドするためのドメイン知識を提供します。
- 実行パスを制限し、試行錯誤のコストを削減し、タスク完了の一貫性を向上させます。
- 複雑なプロセスを再利用可能かつ反復可能にし、徐々に安定した SOP を形成します。
ツールの機能を「ハードウェア インターフェイス」に例えると、スキルは「やり方」を定義する「操作説明書」や「ベスト プラクティス集」に似ています。
2. 進歩的開示: 状況のジレンマを解決する
エージェント スキルの中核となる革新は、プログレッシブ ディスクロージャです。つまり、コンテキスト ウィンドウに一度に大量のコンテンツが詰め込まれないように、オンデマンドで情報をロードします。
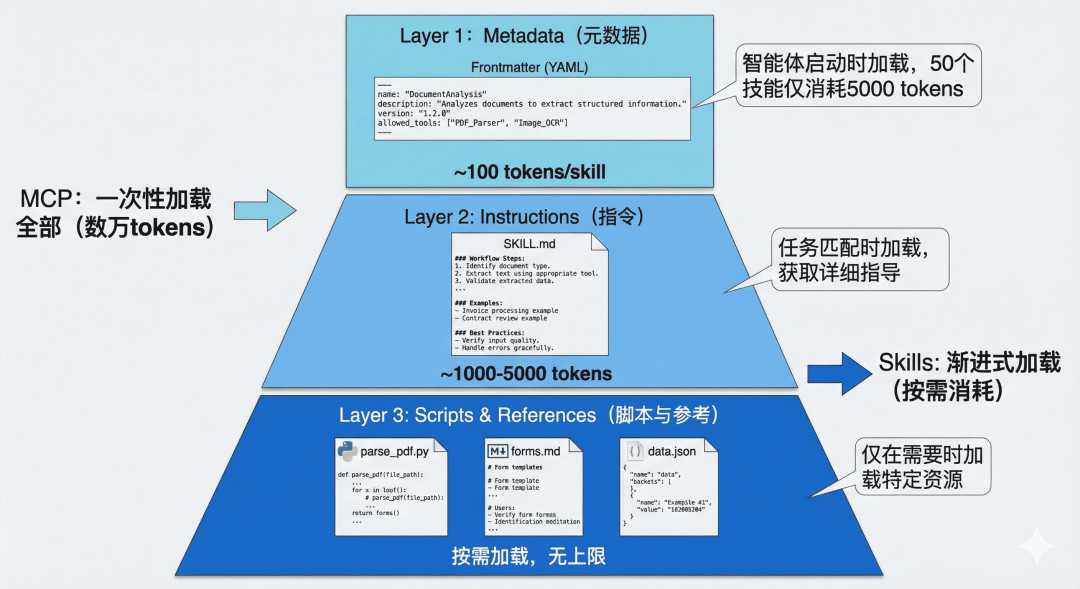
2.1 最初の層: メタデータ
通常、各スキルは別のフォルダーにあり、コア ファイルは SKILL.md です。ファイルは、スキルの基本情報を定義する YAML Frontmatter で始まります。
エージェントが起動すると、すべてのスキルのフロントマターのみが読み取られ、システム プロンプト ワードが挿入されます。実際の経験に基づいて:
- 1 つのスキル メタデータは約
100 tokensを消費します - 50 スキルのコストは約
5,000 tokens
2.2 第 2 レベル: スキル本体 (指示)
スキルが現在のタスクとの関連性が高いと判断された場合、エージェントは完全な SKILL.md を読み取り、詳細な手順、注意事項、例をロードします。
トークン消費のこの部分は通常、スキルの複雑さに関連しており、一般的な範囲は次のとおりです。
1,000~5,000 tokens
2.3 3 番目の層: 追加リソース (スクリプトとリファレンス)
複雑なスキルは、SKILL.md のスクリプト、構成、参照ドキュメントを参照し、必要な場合にのみそれらをロードできます。
ディレクトリ構造の例:
|
|
一般的な呼び出し方法:
- PDFを解析する必要がある場合は、
parse_pdf.pyを実行してください。 - フォーム入力タスクが発生した場合は、
forms.mdを再度ロードします。 - テンプレート ファイルは、ドキュメントを特定の形式で出力する場合にのみアクセスされます
3. この設計が機能する理由
3.1 スケーラブルな知識能力
「スクリプト + 外部ファイル」を使用すると、スキルによってコンテキスト ウィンドウの容量をはるかに超える知識を得ることができます。
たとえば、データ分析スキルには 1GB データ ファイルとクエリ スクリプトが付属しており、エージェントはデータ セット全体をコンテキストに直接接続するのではなく、スクリプトを実行することによってデータにアクセスします。
3.2 より強い確実性
複雑な計算、データ変換、および形式解析をコード実行に処理することで、プレーン テキスト生成における LLM の不確実性と幻覚リスクを大幅に軽減できます。
4. 実際の効果: 16,000 から 500 トークンまで
コミュニティの実践では、段階的な開示により、初期コンテキストのオーバーヘッドが大幅に削減できることが示されています。
- 従来の MCP 方式: 多数のツール定義を含む MCP サービスに直接接続し、
16,000 tokensについて初期化します。 - スキルのパッケージ化後: 最初に軽量スキルを「ゲートウェイ」として使用し、Frontmatter を通じてのみ機能を記述し、
500 tokensについて初期化します。
タスクが本当に必要な場合は、詳細な手順と追加のリソースがオンデマンドでロードされます。これにより、初期コストが削減されるだけでなく、会話中のコンテキスト管理がより正確になります。
要約する
エージェント スキルの重要な意義は、「利用可能なツール」を「再利用可能な機能」にアップグレードすることです。段階的な開示を通じて、システムは機能の深さを維持しながら、トークンのコストと実行の安定性を大幅に最適化できます。