Agent Skills is a standardized way to package procedural knowledge. In short, it answers not only “whether tools exist” but “how to use them correctly and effectively.”
1. Core Design Principles
The core value of Agent Skills is that it captures reusable methodology:
- It provides domain knowledge to guide how agents combine and invoke tools in specific scenarios.
- It constrains execution paths, reducing trial-and-error and improving consistency.
- It makes complex workflows reusable and iterative, forming stable SOPs over time.
If tool capability is like a hardware interface, Skills is closer to an operations manual plus best-practice playbook, defining what should be done and how.
2. Progressive Disclosure: Solving the Context Bottleneck
The key innovation in Agent Skills is Progressive Disclosure: load information only when needed, instead of pushing everything into the context window at once.
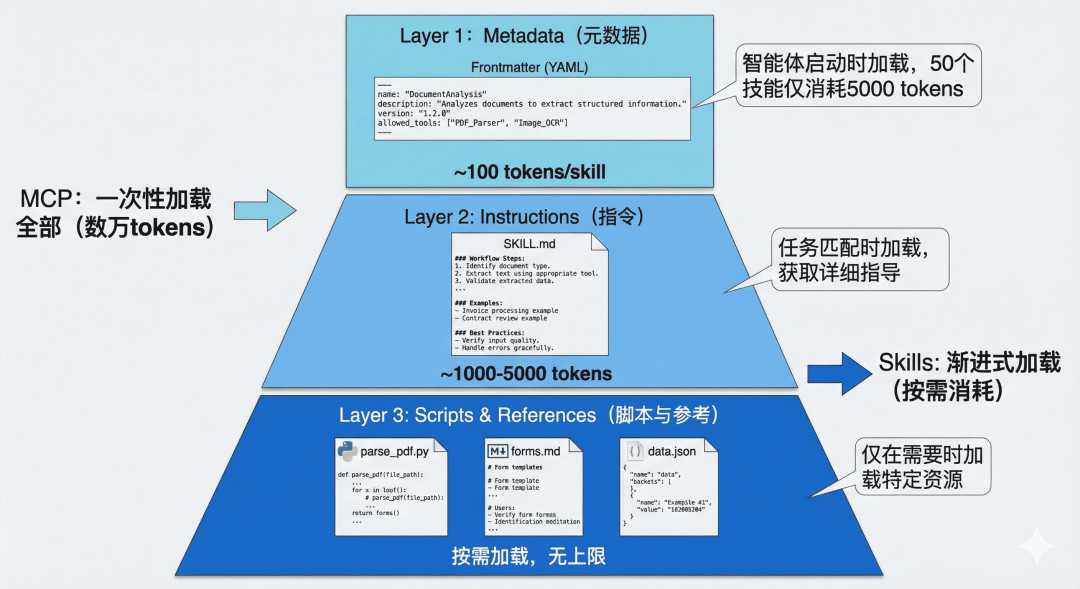
2.1 Layer 1: Metadata
Each skill is usually stored in its own folder, with SKILL.md as the core file. This file starts with YAML front matter that defines basic skill information.
At startup, the agent reads only the front matter of all skills and injects that metadata into the system prompt. In practice:
- Metadata for one skill costs about
100 tokens - 50 skills cost about
5,000 tokens
2.2 Layer 2: Instructions
When a skill is judged highly relevant to the current task, the agent then reads the full SKILL.md, loading detailed instructions, notes, and examples.
Token usage at this layer depends on instruction complexity, typically:
1,000to5,000 tokens
2.3 Layer 3: Additional Resources (Scripts & References)
For more complex skills, SKILL.md can reference scripts, config files, and docs, which are loaded only when needed.
Example directory structure:
|
|
Typical invocation pattern:
- Run
parse_pdf.pywhen PDF parsing is required - Load
forms.mdonly for form-filling tasks - Access template files only when generating specific output formats
3. Why This Design Works
3.1 Scalable Knowledge Capacity
With scripts and external files, a skill can carry knowledge far beyond context-window limits.
For example, a data-analysis skill can include a 1GB dataset plus query scripts, and the agent can access data through execution instead of loading the whole dataset into context.
3.2 Stronger Determinism
Delegating complex computation, data transformation, and format parsing to code significantly reduces uncertainty and hallucination risk in pure text generation.
4. Practical Impact: From 16k to 500 Tokens
Community practice shows that Progressive Disclosure can drastically reduce initial context overhead:
- Traditional MCP approach: directly connect to an MCP server with many tool definitions, around
16,000 tokensat initialization - With Skills packaging: use a lightweight gateway skill described mainly in front matter, around
500 tokensat initialization
Detailed instructions and additional resources are loaded only when the task truly requires them. This lowers initial cost and improves context management precision during the conversation.
Summary
The key value of Agent Skills is upgrading from “tools are available” to “capabilities are reusable.” With Progressive Disclosure, systems can preserve capability depth while significantly optimizing token cost and execution stability.